To enhance the controllability of text-to-image diffusion models, existing efforts like ControlNet incorporated image-based conditional controls. In this paper, we reveal that existing methods still face significant challenges in generating images that align with the image conditional controls. To this end, we propose ControlNet++, a novel approach that improves controllable generation by explicitly optimizing pixel-level cycle consistency between generated images and conditional controls. Specifically, for an input conditional control, we use a pre-trained discriminative reward model to extract the corresponding condition of the generated images, and then optimize the consistency loss between the input conditional control and extracted condition. A straightforward implementation would be generating images from random noises and then calculating the consistency loss, but such an approach requires storing gradients for multiple sampling timesteps, leading to considerable time and memory costs. To address this, we introduce an efficient reward strategy that deliberately disturbs the input images by adding noise, and then uses the single-step denoised images for reward fine-tuning. This avoids the extensive costs associated with image sampling, allowing for more efficient reward fine-tuning. Extensive experiments show that ControlNet++ significantly improves controllability under various conditional controls. For example, it achieves improvements over ControlNet by 7.9% mIoU, 13.4% SSIM, and 7.6% RMSE, respectively, for segmentation mask, line-art edge, and depth conditions.
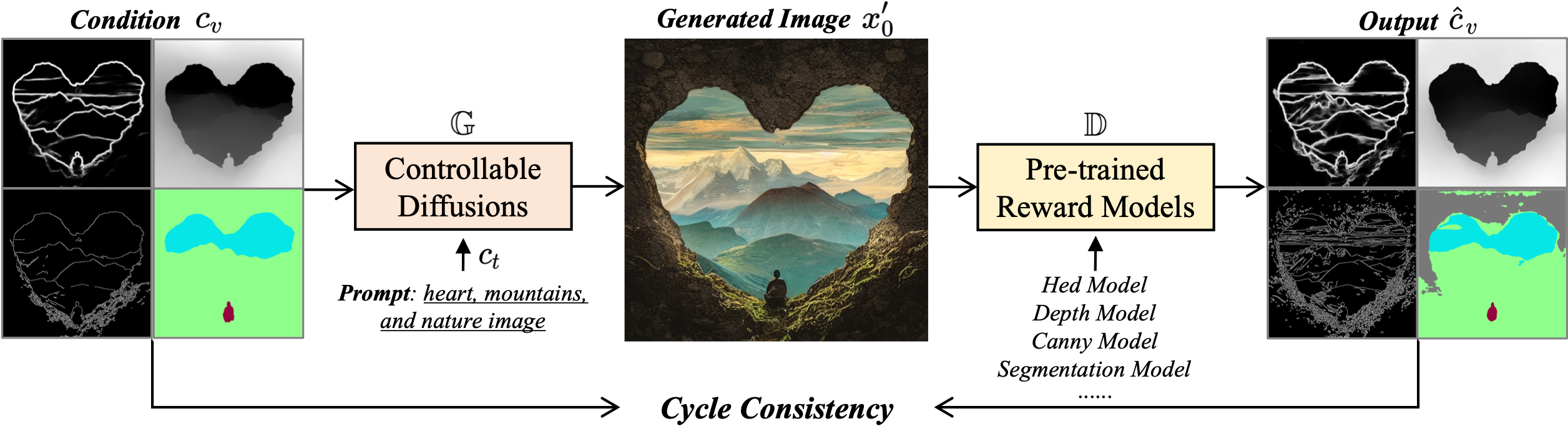
We first prompt the diffusion model \( G \) to generate an image \( x'_0 \) based on the given image condition \( c_v \) and text prompt \( c_t \), then extract the corresponding image condition \( \hat{c}_v \) from the generated image \( x'_0 \) using pre-trained discriminative models \( D \). The cycle consistency is defined as the similarity between the extracted condition \( \hat{c}_v \) and input condition \( c_v \).
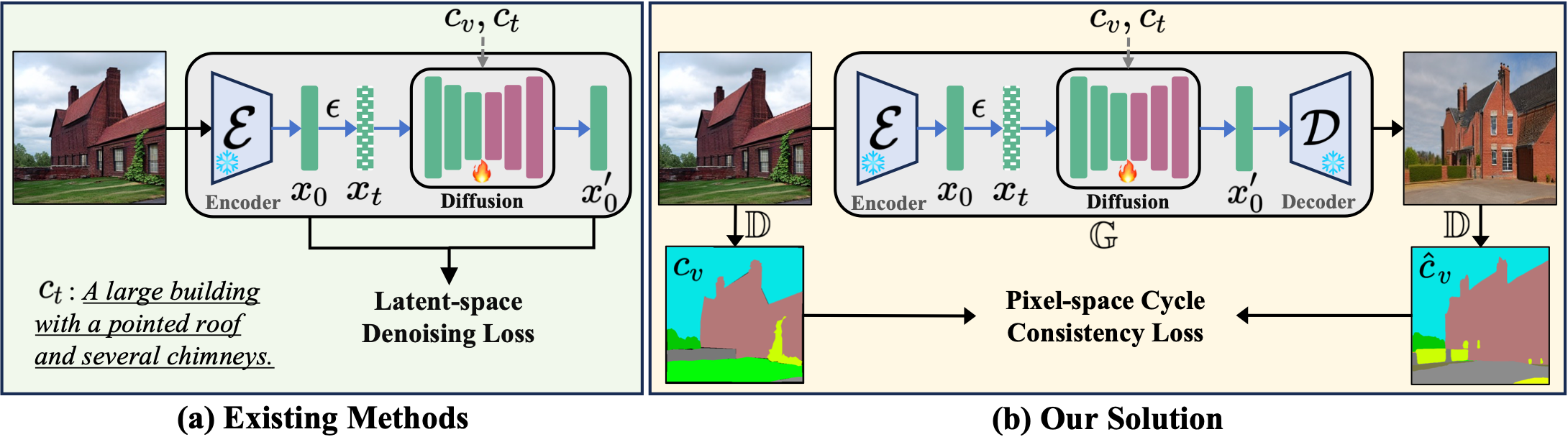
(a) Existing methods achieve implicit controllability by introducing imagebased conditional control \( c_v \) into the denoising process of diffusion models, with the guidance of latent-space denoising loss. (b) We utilize discriminative reward models \( D \) to explicitly optimize the controllability of G via pixel-level cycle consistency loss.
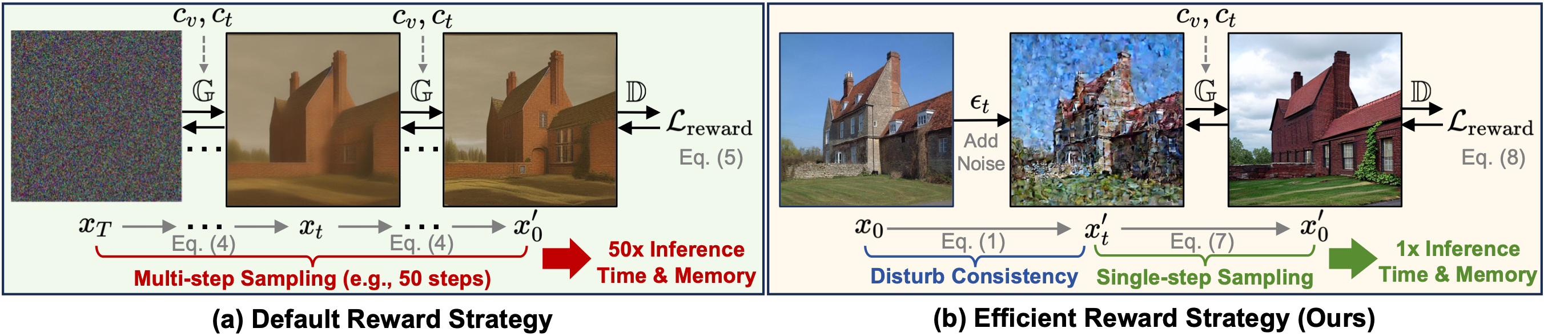
(a) Pipeline of default reward fine-tuning strategy. Reward fine-tuning requires sampling all the way to the full image. Such a method needs to keep all gradients for each timestep and the memory required is unbearable by current GPUs. (b) Pipeline of our efficient reward strategy. We add a small noise \( \epsilon_t (t \leq t_{thre} ) \) to disturb the consistency between input images and conditions, then the single-step denoised image can be directly used for efficient reward fine-tuning.

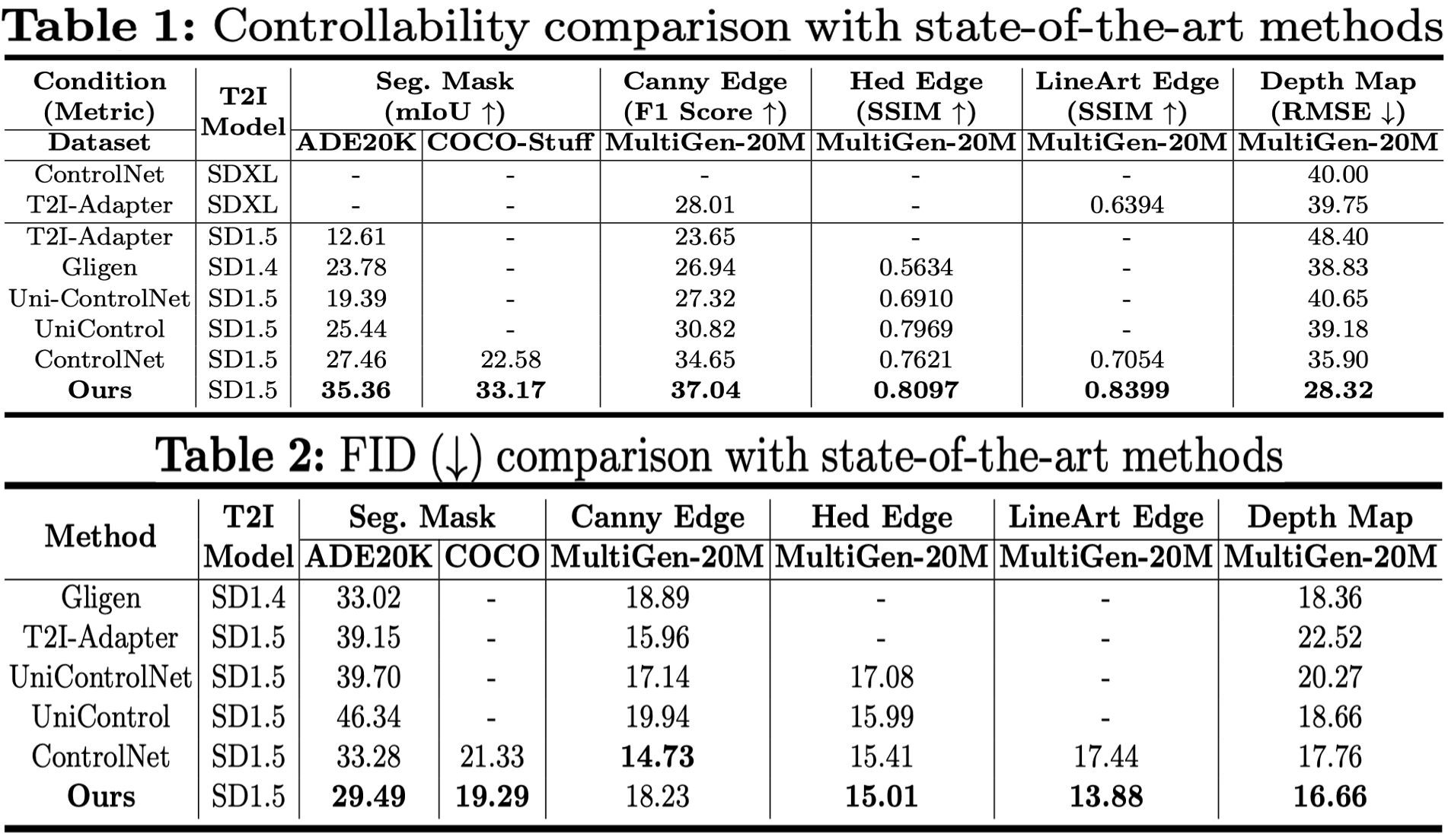
We achieves significant controllability improvements without sacrificing image quality (FID).
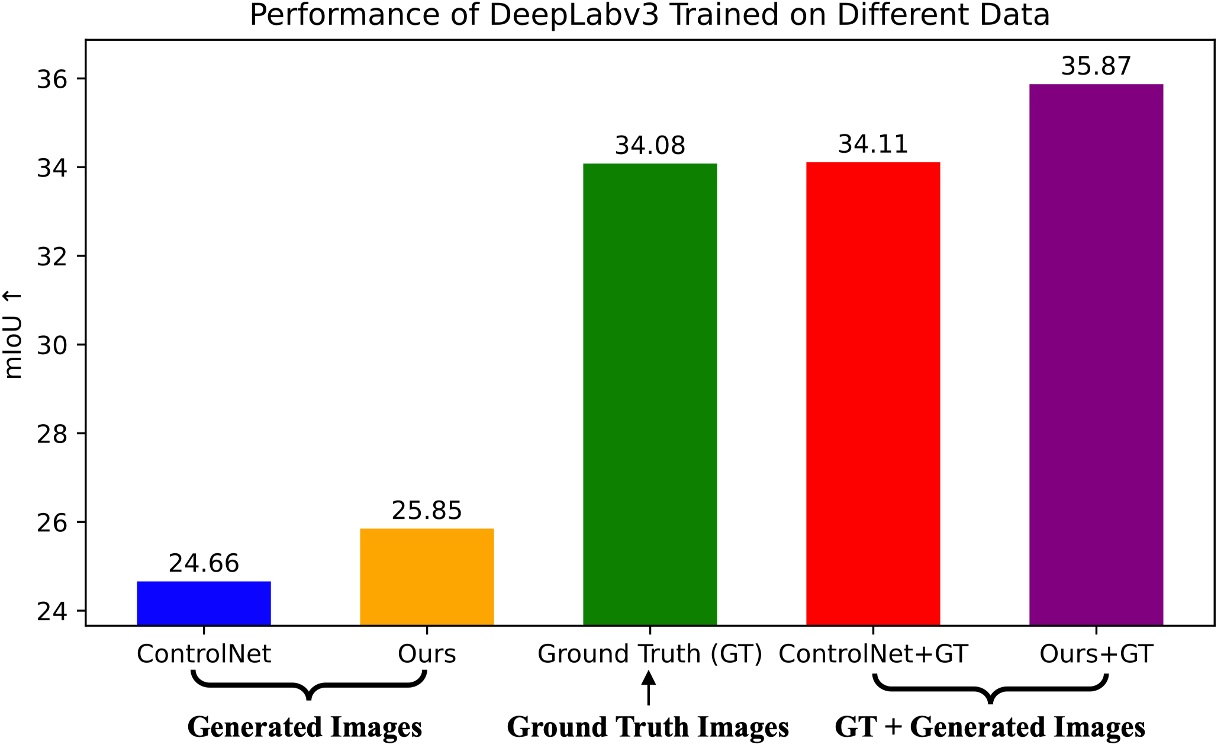
To further validate our improvements in controllability and their impact, we use the generated images along with real human-annotated labels to create a new dataset for training discriminative models from scratch. The segmentation model trained on our images outperforms the baseline results (ControlNet) by a large margin. Please note that this improvement is significant in segmentation tasks.






@article{li2024controlnet,
author = {Ming Li, Taojiannan Yang, Huafeng Kuang, Jie Wu, Zhaoning Wang, Xuefeng Xiao, Chen Chen},
title = {ControlNet++: Improving Conditional Controls with Efficient Consistency Feedback},
journal = {arXiv preprint arXiv:2404.07987},
year = {2024},
} 